Making arithmetic Ops on double¶
Now that we have a double type, we have yet to use it to perform
computations. We’ll start by defining multiplication.
Op’s contract¶
An Op is any object which inherits from gof.Op. It has to
define the following methods.
-
make_node(*inputs)¶ This method is responsible for creating output Variables of a suitable symbolic Type to serve as the outputs of this Op’s application. The Variables found in
*inputsmust be operated on using Theano’s symbolic language to compute the symbolic output Variables. This method should put these outputs into an Apply instance, and return the Apply instance.This method creates an Apply node representing the application of the Op on the inputs provided. If the Op cannot be applied to these inputs, it must raise an appropriate exception.
The inputs of the Apply instance returned by this call must be ordered correctly: a subsequent
self.make_node(*apply.inputs)must produce something equivalent to the firstapply.
-
perform(node, inputs, output_storage)¶ This method computes the function associated to this Op.
nodeis an Apply node created by the Op’smake_nodemethod.inputsis a list of references to data to operate on using non-symbolic statements, (i.e., statements in Python, Numpy).output_storageis a list of storage cells where the variables of the computation must be put.More specifically:
node: This is a reference to an Apply node which was previously obtained via theOp’smake_nodemethod. It is typically not used in simple Ops, but it contains symbolic information that could be required for complex Ops.inputs: This is a list of data from which the values stored inoutput_storageare to be computed using non-symbolic language.output_storage: This is a list of storage cells where the output is to be stored. A storage cell is a one-element list. It is forbidden to change the length of the list(s) contained inoutput_storage. There is one storage cell for each output of the Op.The data put in
output_storagemust match the type of the symbolic output. This is a situation where thenodeargument can come in handy.A function Mode may allow
output_storageelements to persist between evaluations, or it may resetoutput_storagecells to hold a value ofNone. It can also pre-allocate some memory for the Op to use. This feature can allowperformto reuse memory between calls, for example. If there is something preallocated in theoutput_storage, it will be of the good dtype, but can have the wrong shape and have any stride pattern.
This method must be determined by the inputs. That is to say, if it is evaluated once on inputs A and returned B, then if ever inputs C, equal to A, are presented again, then outputs equal to B must be returned again.
You must be careful about aliasing outputs to inputs, and making modifications to any of the inputs. See Views and inplace operations before writing a
performimplementation that does either of these things.
Instead (or in addition to) perform() You can also provide a
C implementation of For more details, refer to the
documentation for Op.
-
__eq__(other)¶ otheris also an Op.Returning
Truehere is a promise to the optimization system that the other Op will produce exactly the same graph effects (from perform) as this one, given identical inputs. This means it will produce the same output values, it will destroy the same inputs (same destroy_map), and will alias outputs to the same inputs (same view_map). For more details, see Views and inplace operations.Note
If you set __props__, this will be automatically generated.
-
__hash__()¶ If two Op instances compare equal, then they must return the same hash value.
Equally important, this hash value must not change during the lifetime of self. Op instances should be immutable in this sense.
Note
If you set __props__, this will be automatically generated.
Optional methods or attributes¶
-
__props__¶ Default: Undefined
Must be a tuple. Lists the name of the attributes which influence the computation performed. This will also enable the automatic generation of appropriate __eq__, __hash__ and __str__ methods. Should be set to () if you have no attributes that are relevant to the computation to generate the methods.
New in version 0.7.
-
default_output¶ Default: None
If this member variable is an integer, then the default implementation of
__call__will returnnode.outputs[self.default_output], wherenodewas returned bymake_node. Otherwise, the entire list of outputs will be returned, unless it is of length 1, where the single element will be returned by itself.
-
make_thunk(node, storage_map, compute_map, no_recycling, impl=None)¶ This function must return a thunk, that is a zero-arguments function that encapsulates the computation to be performed by this op on the arguments of the node.
- Parameters
node – Apply instance The node for which a thunk is requested.
storage_map – dict of lists This maps variables to a one-element lists holding the variable’s current value. The one-element list acts as pointer to the value and allows sharing that “pointer” with other nodes and instances.
compute_map – dict of lists This maps variables to one-element lists holding booleans. If the value is 0 then the variable has not been computed and the value should not be considered valid. If the value is 1 the variable has been computed and the value is valid. If the value is 2 the variable has been garbage-collected and is no longer valid, but shouldn’t be required anymore for this call.
no_recycling – WRITEME WRITEME
impl – None, ‘c’ or ‘py’ Which implementation to use.
The returned function must ensure that is sets the computed variables as computed in the compute_map.
Defining this function removes the requirement for
perform()or C code, as you will define the thunk for the computation yourself.
-
__call__(*inputs, **kwargs)¶ By default this is a convenience function which calls
make_node()with the supplied arguments and returns the result indexed by default_output. This can be overridden by subclasses to do anything else, but must return either a theano Variable or a list of Variables.If you feel the need to override __call__ to change the graph based on the arguments, you should instead create a function that will use your Op and build the graphs that you want and call that instead of the Op instance directly.
-
infer_shape(node, shapes)¶ This function is needed for shape optimization.
shapesis a list with one tuple for each input of the Apply node (which corresponds to the inputs of the op). Each tuple contains as many elements as the number of dimensions of the corresponding input. The value of each element is the shape (number of items) along the corresponding dimension of that specific input.While this might sound complicated, it is nothing more than the shape of each input as symbolic variables (one per dimension).
The function should return a list with one tuple for each output. Each tuple should contain the corresponding output’s computed shape.
Implementing this method will allow Theano to compute the output’s shape without computing the output itself, potentially sparing you a costly recomputation.
-
flops(inputs, outputs)¶ It is only used to have more information printed by the memory profiler. It makes it print the mega flops and giga flops per second for each apply node. It takes as inputs two lists: one for the inputs and one for the outputs. They contain tuples that are the shapes of the corresponding inputs/outputs.
-
__str__()¶ This allows you to specify a more informative string representation of your Op. If an Op has parameters, it is highly recommended to have the
__str__method include the name of the op and the Op’s parameters’ values.Note
If you set __props__, this will be automatically generated. You can still overide it for custom output.
-
do_constant_folding(node)¶ Default: Return True
By default when optimizations are enabled, we remove during function compilation Apply nodes whose inputs are all constants. We replace the Apply node with a Theano constant variable. This way, the Apply node is not executed at each function call. If you want to force the execution of an op during the function call, make do_constant_folding return False.
As done in the Alloc op, you can return False only in some cases by analyzing the graph from the node parameter.
-
debug_perform(node, inputs, output_storage)¶ Undefined by default.
If you define this function then it will be used instead of C code or perform() to do the computation while debugging (currently DebugMode, but others may also use it in the future). It has the same signature and contract as
perform().This enables ops that cause trouble with DebugMode with their normal behaviour to adopt a different one when run under that mode. If your op doesn’t have any problems, don’t implement this.
If you want your op to work with gradient.grad() you also need to implement the functions described below.
Gradient¶
These are the function required to work with gradient.grad().
-
grad(inputs, output_gradients)¶ If the Op being defined is differentiable, its gradient may be specified symbolically in this method. Both
inputsandoutput_gradientsare lists of symbolic Theano Variables and those must be operated on using Theano’s symbolic language. The grad method must return a list containing one Variable for each input. Each returned Variable represents the gradient with respect to that input computed based on the symbolic gradients with respect to each output.If the output is not differentiable with respect to an input then this method should be defined to return a variable of type NullType for that input. Likewise, if you have not implemented the grad computation for some input, you may return a variable of type NullType for that input. theano.gradient contains convenience methods that can construct the variable for you:
theano.gradient.grad_undefined()andtheano.gradient.grad_not_implemented(), respectively.If an element of output_gradient is of type theano.gradient.DisconnectedType, it means that the cost is not a function of this output. If any of the op’s inputs participate in the computation of only disconnected outputs, then Op.grad should return DisconnectedType variables for those inputs.
If the grad method is not defined, then Theano assumes it has been forgotten. Symbolic differentiation will fail on a graph that includes this Op.
It must be understood that the Op’s grad method is not meant to return the gradient of the Op’s output. theano.tensor.grad computes gradients; Op.grad is a helper function that computes terms that appear in gradients.
If an Op has a single vector-valued output y and a single vector-valued input x, then the grad method will be passed x and a second vector z. Define J to be the Jacobian of y with respect to x. The Op’s grad method should return dot(J.T,z). When theano.tensor.grad calls the grad method, it will set z to be the gradient of the cost C with respect to y. If this op is the only op that acts on x, then dot(J.T,z) is the gradient of C with respect to x. If there are other ops that act on x, theano.tensor.grad will have to add up the terms of x’s gradient contributed by the other op’s grad method.
In practice, an op’s input and output are rarely implemented as single vectors. Even if an op’s output consists of a list containing a scalar, a sparse matrix, and a 4D tensor, you can think of these objects as being formed by rearranging a vector. Likewise for the input. In this view, the values computed by the grad method still represent a Jacobian-vector product.
In practice, it is probably not a good idea to explicitly construct the Jacobian, which might be very large and very sparse. However, the returned value should be equal to the Jacobian-vector product.
So long as you implement this product correctly, you need not understand what theano.tensor.grad is doing, but for the curious the mathematical justification is as follows:
In essence, the grad method must simply implement through symbolic Variables and operations the chain rule of differential calculus. The chain rule is the mathematical procedure that allows one to calculate the total derivative
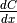 of the
final scalar symbolic Variable C with respect to a primitive
symbolic Variable x found in the list
of the
final scalar symbolic Variable C with respect to a primitive
symbolic Variable x found in the list inputs. The grad method does this usingoutput_gradientswhich provides the total derivative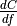 of C with respect to a symbolic
Variable that is returned by the Op (this is provided in
of C with respect to a symbolic
Variable that is returned by the Op (this is provided in
output_gradients), as well as the knowledge of the total derivative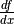 of the latter with respect to the
primitive Variable (this has to be computed).
of the latter with respect to the
primitive Variable (this has to be computed).In mathematics, the total derivative of a scalar variable (C) with respect to a vector of scalar variables (x), i.e. the gradient, is customarily represented as the row vector of the partial derivatives, whereas the total derivative of a vector of scalar variables (f) with respect to another (x), is customarily represented by the matrix of the partial derivatives, i.e.the jacobian matrix. In this convenient setting, the chain rule instructs that the gradient of the final scalar variable C with respect to the primitive scalar variables in x through those in f is simply given by the matrix product:
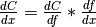 .
.Here, the chain rule must be implemented in a similar but slightly more complex setting: Theano provides in the list
output_gradientsone gradient for each of the Variables returned by the Op. Where f is one such particular Variable, the corresponding gradient found inoutput_gradientsand representing is provided with a shape
similar to f and thus not necessarily as a row vector of scalars.
Furthermore, for each Variable x of the Op’s list of input variables
inputs, the returned gradient representing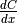 must have a shape similar to that of Variable x.
must have a shape similar to that of Variable x.If the output list of the op is
![[f_1, ... f_n]](../_images/math/9119289ee92e7da53ca943b6855b25ab592004ab.png) , then the
list
, then the
list output_gradientsis![[grad_{f_1}(C), grad_{f_2}(C),
... , grad_{f_n}(C)]](../_images/math/e8dfb821739d6c5e2b714bf5c6e4533ff54ace4e.png) . If
. If inputsconsists of the list![[x_1, ..., x_m]](../_images/math/803c4d7c98916a5302ac241179722ff5334f21f0.png) , then Op.grad should return the list
, then Op.grad should return the list
![[grad_{x_1}(C), grad_{x_2}(C), ..., grad_{x_m}(C)]](../_images/math/3d9b397a200bd0333058ec1cfdf0822eef153728.png) , where
, where
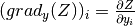 (and
(and
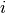 can stand for multiple dimensions).
can stand for multiple dimensions).In other words,
grad()does not return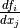 , but instead the appropriate dot product specified by the
chain rule:
, but instead the appropriate dot product specified by the
chain rule: 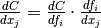 . Both the partial differentiation and the
multiplication have to be performed by
. Both the partial differentiation and the
multiplication have to be performed by grad().Theano currently imposes the following constraints on the values returned by the grad method:
They must be Variable instances.
When they are types that have dtypes, they must never have an integer dtype.
The output gradients passed to Op.grad will also obey these constraints.
Integers are a tricky subject. Integers are the main reason for having DisconnectedType, NullType or zero gradient. When you have an integer as an argument to your grad method, recall the definition of a derivative to help you decide what value to return:
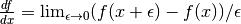 .
.Suppose your function f has an integer-valued output. For most functions you’re likely to implement in theano, this means your gradient should be zero, because f(x+epsilon) = f(x) for almost all x. (The only other option is that the gradient could be undefined, if your function is discontinuous everywhere, like the rational indicator function)
Suppose your function f has an integer-valued input. This is a little trickier, because you need to think about what you mean mathematically when you make a variable integer-valued in theano. Most of the time in machine learning we mean “f is a function of a real-valued x, but we are only going to pass in integer-values of x”. In this case, f(x+epsilon) exists, so the gradient through f should be the same whether x is an integer or a floating point variable. Sometimes what we mean is “f is a function of an integer-valued x, and f is only defined where x is an integer.” Since f(x+epsilon) doesn’t exist, the gradient is undefined. Finally, many times in theano, integer valued inputs don’t actually affect the elements of the output, only its shape.
If your function f has both an integer-valued input and an integer-valued output, then both rules have to be combined:
If f is defined at (x+epsilon), then the input gradient is defined. Since f(x+epsilon) would be equal to f(x) almost everywhere, the gradient should be 0 (first rule).
If f is only defined where x is an integer, then the gradient is undefined, regardless of what the gradient with respect to the output is.
Examples:
- f(x,y) = dot product between x and y. x and y are integers.
Since the output is also an integer, f is a step function. Its gradient is zero almost everywhere, so Op.grad should return zeros in the shape of x and y.
- f(x,y) = dot product between x and y. x is floating point and y is an integer.
In this case the output is floating point. It doesn’t matter that y is an integer. We consider f to still be defined at f(x,y+epsilon). The gradient is exactly the same as if y were floating point.
- f(x,y) = argmax of x along axis y.
The gradient with respect to y is undefined, because f(x,y) is not defined for floating point y. How could you take an argmax along a fraActional axis? The gradient with respect to x is 0, because f(x+epsilon, y) = f(x) almost everywhere.
- f(x,y) = a vector with y elements, each of which taking on the value x
The grad method should return DisconnectedType()() for y, because the elements of f don’t depend on y. Only the shape of f depends on y. You probably also want to implement a connection_pattern method to encode this.
- f(x) = int(x) converts float x into an int. g(y) = float(y) converts an integer y into a float.
If the final cost C = 0.5 * g(y) = 0.5 g(f(x)), then the gradient with respect to y will be 0.5, even if y is an integer. However, the gradient with respect to x will be 0, because the output of f is integer-valued.
-
connection_pattern(node): Sometimes needed for proper operation of gradient.grad().
Returns a list of list of bools.
Op.connection_pattern[input_idx][output_idx] is true if the elements of inputs[input_idx] have an effect on the elements of outputs[output_idx].
The
nodeparameter is needed to determine the number of inputs. Some ops such as Subtensor take a variable number of inputs.If no connection_pattern is specified, gradient.grad will assume that all inputs have some elements connected to some elements of all outputs.
This method conveys two pieces of information that are otherwise not part of the theano graph:
Which of the op’s inputs are truly ancestors of each of the op’s outputs. Suppose an op has two inputs, x and y, and outputs f(x) and g(y). y is not really an ancestor of f, but it appears to be so in the theano graph.
Whether the actual elements of each input/output are relevant to a computation. For example, the shape op does not read its input’s elements, only its shape metadata. d shape(x) / dx should thus raise a disconnected input exception (if these exceptions are enabled). As another example, the elements of the Alloc op’s outputs are not affected by the shape arguments to the Alloc op.
Failing to implement this function for an op that needs it can result in two types of incorrect behavior:
gradient.grad erroneously raising a TypeError reporting that a gradient is undefined.
gradient.grad failing to raise a ValueError reporting that an input is disconnected.
Even if connection_pattern is not implemented correctly, if gradient.grad returns an expression, that expression will be numerically correct.
-
R_op(inputs, eval_points)¶ Optional, to work with gradient.R_op().
This function implements the application of the R-operator on the function represented by your op. Let assume that function is
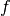 ,
with input
,
with input 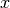 , applying the R-operator means computing the
Jacobian of and right-multiplying it by
, applying the R-operator means computing the
Jacobian of and right-multiplying it by  , the evaluation
point, namely:
, the evaluation
point, namely: 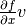 .
.inputsare the symbolic variables corresponding to the value of the input where you want to evaluate the jacobian, andeval_pointsare the symbolic variables corresponding to the value you want to right multiply the jacobian with.Same conventions as for the grad method hold. If your op is not differentiable, you can return None. Note that in contrast to the method
grad(), forR_op()you need to return the same number of outputs as there are ouputs of the op. You can think of it in the following terms. You have all your inputs concatenated into a single vector. You do the same with the evaluation
points (which are as many as inputs and of the shame shape) and obtain
another vector . For each output, you reshape it into a vector,
compute the jacobian of that vector with respect to and
multiply it by . As a last step you reshape each of these
vectors you obtained for each outputs (that have the same shape as
the outputs) back to their corresponding shapes and return them as the
output of the R_op()method.
Defining an Op: mul¶
We’ll define multiplication as a binary operation, even though a multiplication Op could take an arbitrary number of arguments.
First, we’ll instantiate a mul Op:
from theano import gof
mul = gof.Op()
make_node
This function must take as many arguments as the operation we are
defining is supposed to take as inputs—in this example that would be
two. This function ensures that both inputs have the double type.
Since multiplying two doubles yields a double, this function makes an
Apply node with an output Variable of type double.
def make_node(x, y):
if x.type != double or y.type != double:
raise TypeError('mul only works on doubles')
return gof.Apply(mul, [x, y], [double()])
mul.make_node = make_node
The first two lines make sure that both inputs are Variables of the
double type that we created in the previous section. We would not
want to multiply two arbitrary types, it would not make much sense
(and we’d be screwed when we implement this in C!)
The last line is the meat of the definition. There we create an Apply
node representing the application of Op mul to inputs x and
y, giving a Variable instance of type double as the output.
Note
Theano relies on the fact that if you call the make_node method
of Apply’s first argument on the inputs passed as the Apply’s
second argument, the call will not fail and the returned Apply
instance will be equivalent. This is how graphs are copied.
perform
This code actually computes the function.
In our example, the data in inputs will be instances of Python’s
built-in type float because this is the type that double.filter()
will always return, per our own definition. output_storage will
contain a single storage cell for the multiplication’s variable.
def perform(node, inputs, output_storage):
x, y = inputs[0], inputs[1]
z = output_storage[0]
z[0] = x * y
mul.perform = perform
Here, z is a list of one element. By default, z == [None].
Note
It is possible that z does not contain None. If it contains
anything else, Theano guarantees that whatever it contains is what
perform put there the last time it was called with this
particular storage. Furthermore, Theano gives you permission to do
whatever you want with z’s contents, chiefly reusing it or the
memory allocated for it. More information can be found in the
Op documentation.
Warning
We gave z the Theano type double in make_node, which means
that a Python float must be put there. You should not put, say, an
int in z[0] because Theano assumes Ops handle typing properly.
Trying out our new Op¶
In the following code, we use our new Op:
>>> import theano
>>> x, y = double('x'), double('y')
>>> z = mul(x, y)
>>> f = theano.function([x, y], z)
>>> f(5, 6)
30.0
>>> f(5.6, 6.7)
37.519999999999996
Note that there is an implicit call to
double.filter() on each argument, so if we give integers as inputs
they are magically cast to the right type. Now, what if we try this?
>>> x = double('x')
>>> z = mul(x, 2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/u/breuleuo/hg/theano/theano/gof/op.py", line 207, in __call__
File "<stdin>", line 2, in make_node
AttributeError: 'int' object has no attribute 'type'
Automatic Constant Wrapping¶
Well, OK. We’d like our Op to be a bit more flexible. This can be done
by modifying make_node to accept Python int or float as
x and/or y:
def make_node(x, y):
if isinstance(x, (int, float)):
x = gof.Constant(double, x)
if isinstance(y, (int, float)):
y = gof.Constant(double, y)
if x.type != double or y.type != double:
raise TypeError('mul only works on doubles')
return gof.Apply(mul, [x, y], [double()])
mul.make_node = make_node
Whenever we pass a Python int or float instead of a Variable as x or
y, make_node will convert it to Constant for us. gof.Constant
is a Variable we statically know the value of.
>>> import numpy
>>> x = double('x')
>>> z = mul(x, 2)
>>> f = theano.function([x], z)
>>> f(10)
20.0
>>> numpy.allclose(f(3.4), 6.8)
True
Now the code works the way we want it to.
Note
Most Theano Ops follow this convention of up-casting literal
make_node arguments to Constants.
This makes typing expressions more natural. If you do
not want a constant somewhere in your graph, you have to pass a Variable
(like double('x') here).
Final version¶
The above example is pedagogical. When you define other basic arithmetic
operations add, sub and div, code for make_node can be
shared between these Ops. Here is revised implementation of these four
arithmetic operators:
from theano import gof
class BinaryDoubleOp(gof.Op):
__props__ = ("name", "fn")
def __init__(self, name, fn):
self.name = name
self.fn = fn
def make_node(self, x, y):
if isinstance(x, (int, float)):
x = gof.Constant(double, x)
if isinstance(y, (int, float)):
y = gof.Constant(double, y)
if x.type != double or y.type != double:
raise TypeError('%s only works on doubles' % self.name)
return gof.Apply(self, [x, y], [double()])
def perform(self, node, inp, out):
x, y = inp
z, = out
z[0] = self.fn(x, y)
def __str__(self):
return self.name
add = BinaryDoubleOp(name='add',
fn=lambda x, y: x + y)
sub = BinaryDoubleOp(name='sub',
fn=lambda x, y: x - y)
mul = BinaryDoubleOp(name='mul',
fn=lambda x, y: x * y)
div = BinaryDoubleOp(name='div',
fn=lambda x, y: x / y)
Instead of working directly on an instance of Op, we create a subclass of
Op that we can parametrize. All the operations we define are binary. They
all work on two inputs with type double. They all return a single
Variable of type double. Therefore, make_node does the same thing
for all these operations, except for the Op reference self passed
as first argument to Apply. We define perform using the function
fn passed in the constructor.
This design is a flexible way to define basic operations without duplicating code. The same way a Type subclass represents a set of structurally similar types (see previous section), an Op subclass represents a set of structurally similar operations: operations that have the same input/output types, operations that only differ in one small detail, etc. If you see common patterns in several Ops that you want to define, it can be a good idea to abstract out what you can. Remember that an Op is just an object which satisfies the contract described above on this page and that you should use all the tools at your disposal to create these objects as efficiently as possible.
Exercise: Make a generic DoubleOp, where the number of arguments can also be given as a parameter.