More Examples¶
At this point it would be wise to begin familiarizing yourself more systematically with Theano’s fundamental objects and operations by browsing this section of the library: Basic Tensor Functionality.
As the tutorial unfolds, you should also gradually acquaint yourself with the other relevant areas of the library and with the relevant subjects of the documentation entrance page.
Logistic Function¶
Here’s another straightforward example, though a bit more elaborate than adding two numbers together. Let’s say that you want to compute the logistic curve, which is given by:
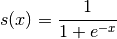
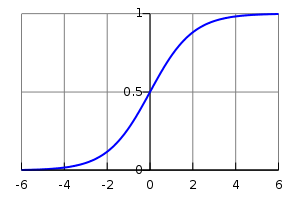
A plot of the logistic function, with x on the x-axis and s(x) on the y-axis.¶
You want to compute the function elementwise on matrices of doubles, which means that you want to apply this function to each individual element of the matrix.
Well, what you do is this:
>>> import theano
>>> import theano.tensor as T
>>> x = T.dmatrix('x')
>>> s = 1 / (1 + T.exp(-x))
>>> logistic = theano.function([x], s)
>>> logistic([[0, 1], [-1, -2]])
array([[ 0.5 , 0.73105858],
[ 0.26894142, 0.11920292]])
The reason logistic is performed elementwise is because all of its operations—division, addition, exponentiation, and division—are themselves elementwise operations.
It is also the case that:
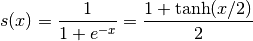
We can verify that this alternate form produces the same values:
>>> s2 = (1 + T.tanh(x / 2)) / 2
>>> logistic2 = theano.function([x], s2)
>>> logistic2([[0, 1], [-1, -2]])
array([[ 0.5 , 0.73105858],
[ 0.26894142, 0.11920292]])
Computing More than one Thing at the Same Time¶
Theano supports functions with multiple outputs. For example, we can compute the elementwise difference, absolute difference, and squared difference between two matrices a and b at the same time:
>>> a, b = T.dmatrices('a', 'b')
>>> diff = a - b
>>> abs_diff = abs(diff)
>>> diff_squared = diff**2
>>> f = theano.function([a, b], [diff, abs_diff, diff_squared])
Note
dmatrices produces as many outputs as names that you provide. It is a shortcut for allocating symbolic variables that we will often use in the tutorials.
When we use the function f, it returns the three variables (the printing was reformatted for readability):
>>> f([[1, 1], [1, 1]], [[0, 1], [2, 3]])
[array([[ 1., 0.],
[-1., -2.]]), array([[ 1., 0.],
[ 1., 2.]]), array([[ 1., 0.],
[ 1., 4.]])]
Setting a Default Value for an Argument¶
Let’s say you want to define a function that adds two numbers, except that if you only provide one number, the other input is assumed to be one. You can do it like this:
>>> from theano import In
>>> from theano import function
>>> x, y = T.dscalars('x', 'y')
>>> z = x + y
>>> f = function([x, In(y, value=1)], z)
>>> f(33)
array(34.0)
>>> f(33, 2)
array(35.0)
This makes use of the In class which allows
you to specify properties of your function’s parameters with greater detail. Here we
give a default value of 1 for y by creating a In instance with
its value field set to 1.
Inputs with default values must follow inputs without default values (like Python’s functions). There can be multiple inputs with default values. These parameters can be set positionally or by name, as in standard Python:
>>> x, y, w = T.dscalars('x', 'y', 'w')
>>> z = (x + y) * w
>>> f = function([x, In(y, value=1), In(w, value=2, name='w_by_name')], z)
>>> f(33)
array(68.0)
>>> f(33, 2)
array(70.0)
>>> f(33, 0, 1)
array(33.0)
>>> f(33, w_by_name=1)
array(34.0)
>>> f(33, w_by_name=1, y=0)
array(33.0)
Note
In does not know the name of the local variables y and w
that are passed as arguments. The symbolic variable objects have name
attributes (set by dscalars in the example above) and these are the
names of the keyword parameters in the functions that we build. This is
the mechanism at work in In(y, value=1). In the case of In(w,
value=2, name='w_by_name'). We override the symbolic variable’s name
attribute with a name to be used for this function.
You may like to see Function in the library for more detail.
Copying functions¶
Theano functions can be copied, which can be useful for creating similar
functions but with different shared variables or updates. This is done using
the copy() method of function objects. The optimized graph of the original function is copied,
so compilation only needs to be performed once.
Let’s start from the accumulator defined above:
>>> import theano
>>> import theano.tensor as T
>>> state = theano.shared(0)
>>> inc = T.iscalar('inc')
>>> accumulator = theano.function([inc], state, updates=[(state, state+inc)])
We can use it to increment the state as usual:
>>> accumulator(10)
array(0)
>>> print(state.get_value())
10
We can use copy() to create a similar accumulator but with its own internal state
using the swap parameter, which is a dictionary of shared variables to exchange:
>>> new_state = theano.shared(0)
>>> new_accumulator = accumulator.copy(swap={state:new_state})
>>> new_accumulator(100)
[array(0)]
>>> print(new_state.get_value())
100
The state of the first function is left untouched:
>>> print(state.get_value())
10
We now create a copy with updates removed using the delete_updates
parameter, which is set to False by default:
>>> null_accumulator = accumulator.copy(delete_updates=True)
As expected, the shared state is no longer updated:
>>> null_accumulator(9000)
[array(10)]
>>> print(state.get_value())
10
Using Random Numbers¶
Because in Theano you first express everything symbolically and afterwards compile this expression to get functions, using pseudo-random numbers is not as straightforward as it is in NumPy, though also not too complicated.
The way to think about putting randomness into Theano’s computations is to put random variables in your graph. Theano will allocate a NumPy RandomStream object (a random number generator) for each such variable, and draw from it as necessary. We will call this sort of sequence of random numbers a random stream. Random streams are at their core shared variables, so the observations on shared variables hold here as well. Theano’s random objects are defined and implemented in RandomStreams and, at a lower level, in RandomStreamsBase.
Brief Example¶
Here’s a brief example. The setup code is:
from theano.tensor.shared_randomstreams import RandomStreams
from theano import function
srng = RandomStreams(seed=234)
rv_u = srng.uniform((2,2))
rv_n = srng.normal((2,2))
f = function([], rv_u)
g = function([], rv_n, no_default_updates=True) #Not updating rv_n.rng
nearly_zeros = function([], rv_u + rv_u - 2 * rv_u)
Here, ‘rv_u’ represents a random stream of 2x2 matrices of draws from a uniform
distribution. Likewise, ‘rv_n’ represents a random stream of 2x2 matrices of
draws from a normal distribution. The distributions that are implemented are
defined in RandomStreams and, at a lower level,
in raw_random. They only work on CPU.
See Other Implementations for GPU version.
Now let’s use these objects. If we call f(), we get random uniform numbers. The internal state of the random number generator is automatically updated, so we get different random numbers every time.
>>> f_val0 = f()
>>> f_val1 = f() #different numbers from f_val0
When we add the extra argument no_default_updates=True to
function (as in g), then the random number generator state is
not affected by calling the returned function. So, for example, calling
g multiple times will return the same numbers.
>>> g_val0 = g() # different numbers from f_val0 and f_val1
>>> g_val1 = g() # same numbers as g_val0!
An important remark is that a random variable is drawn at most once during any single function execution. So the nearly_zeros function is guaranteed to return approximately 0 (except for rounding error) even though the rv_u random variable appears three times in the output expression.
>>> nearly_zeros = function([], rv_u + rv_u - 2 * rv_u)
Seeding Streams¶
Random variables can be seeded individually or collectively.
You can seed just one random variable by seeding or assigning to the
.rng attribute, using .rng.set_value().
>>> rng_val = rv_u.rng.get_value(borrow=True) # Get the rng for rv_u
>>> rng_val.seed(89234) # seeds the generator
>>> rv_u.rng.set_value(rng_val, borrow=True) # Assign back seeded rng
You can also seed all of the random variables allocated by a RandomStreams
object by that object’s seed method. This seed will be used to seed a
temporary random number generator, that will in turn generate seeds for each
of the random variables.
>>> srng.seed(902340) # seeds rv_u and rv_n with different seeds each
Sharing Streams Between Functions¶
As usual for shared variables, the random number generators used for random variables are common between functions. So our nearly_zeros function will update the state of the generators used in function f above.
For example:
>>> state_after_v0 = rv_u.rng.get_value().get_state()
>>> nearly_zeros() # this affects rv_u's generator
array([[ 0., 0.],
[ 0., 0.]])
>>> v1 = f()
>>> rng = rv_u.rng.get_value(borrow=True)
>>> rng.set_state(state_after_v0)
>>> rv_u.rng.set_value(rng, borrow=True)
>>> v2 = f() # v2 != v1
>>> v3 = f() # v3 == v1
Copying Random State Between Theano Graphs¶
In some use cases, a user might want to transfer the “state” of all random
number generators associated with a given theano graph (e.g. g1, with compiled
function f1 below) to a second graph (e.g. g2, with function f2). This might
arise for example if you are trying to initialize the state of a model, from
the parameters of a pickled version of a previous model. For
theano.tensor.shared_randomstreams.RandomStreams and
theano.sandbox.rng_mrg.MRG_RandomStreams
this can be achieved by copying elements of the state_updates parameter.
Each time a random variable is drawn from a RandomStreams object, a tuple is added to the state_updates list. The first element is a shared variable, which represents the state of the random number generator associated with this particular variable, while the second represents the theano graph corresponding to the random number generation process (i.e. RandomFunction{uniform}.0).
An example of how “random states” can be transferred from one theano function to another is shown below.
>>> from __future__ import print_function
>>> import theano
>>> import numpy
>>> import theano.tensor as T
>>> from theano.sandbox.rng_mrg import MRG_RandomStreams
>>> from theano.tensor.shared_randomstreams import RandomStreams
>>> class Graph():
... def __init__(self, seed=123):
... self.rng = RandomStreams(seed)
... self.y = self.rng.uniform(size=(1,))
>>> g1 = Graph(seed=123)
>>> f1 = theano.function([], g1.y)
>>> g2 = Graph(seed=987)
>>> f2 = theano.function([], g2.y)
>>> # By default, the two functions are out of sync.
>>> f1()
array([ 0.72803009])
>>> f2()
array([ 0.55056769])
>>> def copy_random_state(g1, g2):
... if isinstance(g1.rng, MRG_RandomStreams):
... g2.rng.rstate = g1.rng.rstate
... for (su1, su2) in zip(g1.rng.state_updates, g2.rng.state_updates):
... su2[0].set_value(su1[0].get_value())
>>> # We now copy the state of the theano random number generators.
>>> copy_random_state(g1, g2)
>>> f1()
array([ 0.59044123])
>>> f2()
array([ 0.59044123])
Other Random Distributions¶
There are other distributions implemented.
A Real Example: Logistic Regression¶
The preceding elements are featured in this more realistic example. It will be used repeatedly.
import numpy
import theano
import theano.tensor as T
rng = numpy.random
N = 400 # training sample size
feats = 784 # number of input variables
# generate a dataset: D = (input_values, target_class)
D = (rng.randn(N, feats), rng.randint(size=N, low=0, high=2))
training_steps = 10000
# Declare Theano symbolic variables
x = T.dmatrix("x")
y = T.dvector("y")
# initialize the weight vector w randomly
#
# this and the following bias variable b
# are shared so they keep their values
# between training iterations (updates)
w = theano.shared(rng.randn(feats), name="w")
# initialize the bias term
b = theano.shared(0., name="b")
print("Initial model:")
print(w.get_value())
print(b.get_value())
# Construct Theano expression graph
p_1 = 1 / (1 + T.exp(-T.dot(x, w) - b)) # Probability that target = 1
prediction = p_1 > 0.5 # The prediction thresholded
xent = -y * T.log(p_1) - (1-y) * T.log(1-p_1) # Cross-entropy loss function
cost = xent.mean() + 0.01 * (w ** 2).sum()# The cost to minimize
gw, gb = T.grad(cost, [w, b]) # Compute the gradient of the cost
# w.r.t weight vector w and
# bias term b
# (we shall return to this in a
# following section of this tutorial)
# Compile
train = theano.function(
inputs=[x,y],
outputs=[prediction, xent],
updates=((w, w - 0.1 * gw), (b, b - 0.1 * gb)))
predict = theano.function(inputs=[x], outputs=prediction)
# Train
for i in range(training_steps):
pred, err = train(D[0], D[1])
print("Final model:")
print(w.get_value())
print(b.get_value())
print("target values for D:")
print(D[1])
print("prediction on D:")
print(predict(D[0]))